
In the rapidly evolving landscape of artificial intelligence, generative AI systems have become a cornerstone of innovation, driving advancements in fields ranging from language processing to creative content generation. However, a recent report by the National Institute of Standards and Technology (NIST) sheds light on the increasing vulnerability of these systems to a range of sophisticated cyber attacks. The report, provides a comprehensive taxonomy of attacks targeting Generative AI (GenAI) systems, revealing the intricate ways in which these technologies can be exploited. The findings are particularly relevant as AI continues to integrate deeper into various sectors, raising concerns about the integrity and privacy implications of these systems.
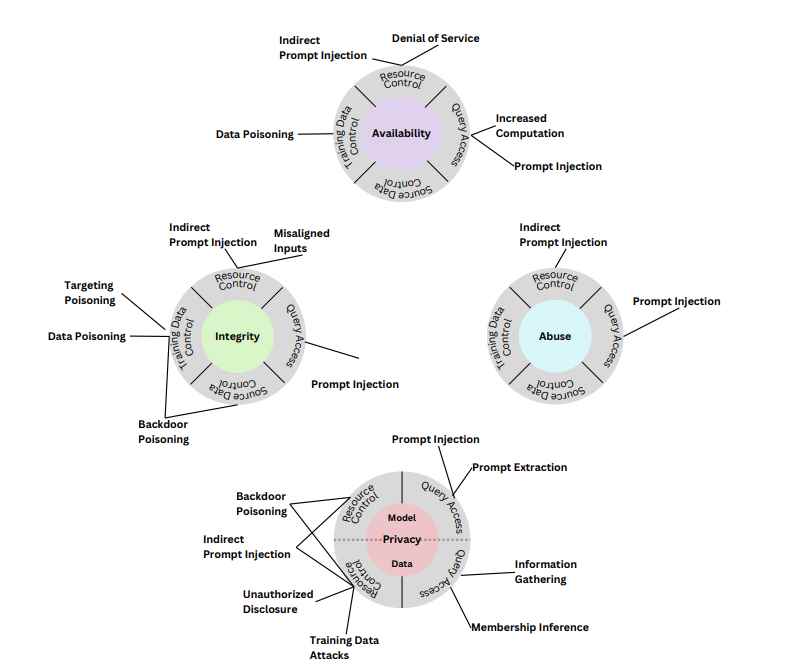
Integrity Attacks: A Threat to AI’s Core
Integrity attacks affecting Generative AI systems are a type of security threat where the goal is to manipulate or corrupt the functioning of the AI system. These attacks can have significant implications, especially as Generative AI systems are increasingly used in various fields. Here are some key aspects of integrity attacks on Generative AI systems:
- Data Poisoning:
- Detail: This attack targets the training phase of an AI model. Attackers inject false or misleading data into the training set, which can subtly or significantly alter the model’s learning. This can result in a model that generates biased or incorrect outputs.
- Example: Consider a facial recognition system being trained with a dataset that has been poisoned with subtly altered images. These images might contain small, imperceptible changes that cause the system to incorrectly recognize certain faces or objects.
- Model Tampering:
- Detail: In this attack, the internal parameters or architecture of the AI model are altered. This could be done by an insider with access to the model or by exploiting a vulnerability in the system.
- Example: An attacker could alter the weightings in a sentiment analysis model, causing it to interpret negative sentiments as positive, which could be particularly damaging in contexts like customer feedback analysis.
- Output Manipulation:
- Detail: This occurs post-processing, where the AI’s output is intercepted and altered before it reaches the end-user. This can be done without directly tampering with the AI model itself.
- Example: If a Generative AI system is used to generate financial reports, an attacker could intercept and manipulate the output to show incorrect financial health, affecting stock prices or investor decisions.
- Adversarial Attacks:
- Detail: These attacks use inputs that are specifically designed to confuse the AI model. These inputs are often indistinguishable from normal inputs to the human eye but cause the AI to make errors.
- Example: A stop sign with subtle stickers or graffiti might be recognized as a speed limit sign by an autonomous vehicle’s AI system, leading to potential traffic violations or accidents.
- Backdoor Attacks:
- Detail: A backdoor is embedded into the AI model during its training. This backdoor is activated by certain inputs, causing the model to behave unexpectedly or maliciously.
- Example: A language translation model could have a backdoor that, when triggered by a specific phrase, starts inserting or altering words in a translation, potentially changing the message’s meaning.
- Exploitation of Biases:
- Detail: This attack leverages existing biases within the AI model. AI systems can inherit biases from their training data, and these biases can be exploited to produce skewed or harmful outputs.
- Example: If an AI model used for resume screening has an inherent gender bias, attackers can submit resumes that are tailored to exploit this bias, increasing the likelihood of certain candidates being selected or rejected unfairly.
- Evasion Attacks:
- Detail: In this scenario, the input data is manipulated in such a way that the AI system fails to recognize it as something it is trained to detect or categorize correctly.
- Example: Malware could be designed to evade detection by an AI-powered security system by altering its code signature slightly, making it appear benign to the system while still carrying out malicious functions.
Privacy attacks on Generative AI
Privacy attacks on Generative AI systems are a serious concern, especially given the increasing use of these systems in handling sensitive data. These attacks aim to compromise the confidentiality and privacy of the data used by or generated from these systems. Here are some common types of privacy attacks, explained in detail with examples:
- Model Inversion Attacks:
- Detail: In this type of attack, the attacker tries to reconstruct the input data from the model’s output. This is particularly concerning if the AI model outputs something that indirectly reveals sensitive information about the input data.
- Example: Consider a facial recognition system that outputs the likelihood of certain attributes (like age or ethnicity). An attacker could use this output information to reconstruct the faces of individuals in the training data, thereby invading their privacy.
- Membership Inference Attacks:
- Detail: These attacks aim to determine whether a particular data record was used in the training dataset of a machine learning model. This can be a privacy concern if the training data contains sensitive information.
- Example: An attacker might test an AI health diagnostic tool with specific patient data. If the model’s predictions are unusually accurate or certain, it might indicate that the patient’s data was part of the training set, potentially revealing sensitive health information.
- Training Data Extraction:
- Detail: Here, the attacker aims to extract actual data points from the training dataset of the AI model. This can be achieved by analyzing the model’s responses to various inputs.
- Example: An attacker could interact with a language model trained on confidential documents and, through carefully crafted queries, could cause the model to regurgitate snippets of these confidential texts.
- Reconstruction Attacks:
- Detail: Similar to model inversion, this attack focuses on reconstructing the input data, often in a detailed and high-fidelity manner. This is particularly feasible in models that retain a lot of information about their training data.
- Example: In a generative model trained to produce images based on descriptions, an attacker might find a way to input specific prompts that cause the model to generate images closely resembling those in the training set, potentially revealing private or sensitive imagery.
- Property Inference Attacks:
- Detail: These attacks aim to infer properties or characteristics of the training data that the model was not intended to reveal. This could expose sensitive attributes or trends in the data.
- Example: An attacker might analyze the output of a model used for employee performance evaluations to infer unprotected characteristics of the employees (like gender or race), which could be used for discriminatory purposes.
- Model Stealing or Extraction:
- Detail: In this case, the attacker aims to replicate the functionality of a proprietary AI model. By querying the model extensively and observing its outputs, the attacker can create a similar model without access to the original training data.
- Example: A competitor could use the public API of a machine learning model to systematically query it and use the responses to train a new model that mimics the original, effectively stealing the intellectual property.
Segmenting Attacks
Attacks on AI systems, including ChatGPT and other generative AI models, can be further categorized based on the stage of the learning process they target (training or inference) and the attacker’s knowledge and access level (white-box or black-box). Here’s a breakdown:
By Learning Stage:
- Attacks during Training Phase:
- Data Poisoning: Injecting malicious data into the training set to compromise the model’s learning process.
- Backdoor Attacks: Embedding hidden functionalities in the model during training that can be activated by specific inputs.
- Attacks during Inference Phase:
- Adversarial Attacks: Presenting misleading inputs to trick the model into making errors during its operation.
- Model Inversion and Reconstruction Attacks: Attempting to infer or reconstruct input data from the model’s outputs.
- Membership Inference Attacks: Determining whether specific data was used in the training set by observing the model’s behavior.
- Property Inference Attacks: Inferring properties of the training data not intended to be disclosed.
- Output Manipulation: Altering the model’s output after it has been generated but before it reaches the intended recipient.
By Attacker’s Knowledge and Access:
- White-Box Attacks (Attacker has full knowledge and access):
- Model Tampering: Directly altering the model’s parameters or structure.
- Backdoor Attacks: Implanting a backdoor during the model’s development, which the attacker can later exploit.
- These attacks require deep knowledge of the model’s architecture, parameters, and potentially access to the training process.
- Black-Box Attacks (Attacker has limited or no knowledge and access):
- Adversarial Attacks: Creating input samples designed to be misclassified or misinterpreted by the model.
- Model Inversion and Reconstruction Attacks: These do not require knowledge of the model’s internal workings.
- Membership and Property Inference Attacks: Based on the model’s output to certain inputs, without knowledge of its internal structure.
- Training Data Extraction: Extracting information about the training data through extensive interaction with the model.
- Model Stealing or Extraction: Replicating the model’s functionality by observing its inputs and outputs.
Implications:
- Training Phase Attacks often require insider access or a significant breach in the data pipeline, making them less common but potentially more devastating.
- Inference Phase Attacks are more accessible to external attackers as they can often be executed with minimal access to the model.
- White-Box Attacks are typically more sophisticated and require a higher level of access and knowledge, often limited to insiders or through major security breaches.
- Black-Box Attacks are more common in real-world scenarios, as they can be executed with limited knowledge about the model and without direct access to its internals.
Understanding these categories helps in devising targeted defense strategies for each type of attack, depending on the specific vulnerabilities and operational stages of the AI system.
Hacking ChatGpt
The ChatGPT AI model, like any advanced machine learning system, is potentially vulnerable to various attacks, including privacy and integrity attacks. Let’s explore how these attacks could be or have been used against ChatGPT, focusing on the privacy attacks mentioned earlier:
- Model Inversion Attacks:
- Potential Use Against ChatGPT: An attacker might attempt to use ChatGPT’s responses to infer details about the data it was trained on. For example, if ChatGPT consistently provides detailed and accurate information about a specific, less-known topic, it could indicate the presence of substantial training data on that topic, potentially revealing the nature of the data sources used.
- Membership Inference Attacks:
- Potential Use Against ChatGPT: This type of attack could try to determine if a particular text or type of text was part of ChatGPT’s training data. By analyzing the model’s responses to specific queries, an attacker might guess whether certain data was included in the training set, which could be a concern if the training data included sensitive or private information.
- Training Data Extraction:
- Potential Use Against ChatGPT: Since ChatGPT generates text based on patterns learned from its training data, there’s a theoretical risk that an attacker could manipulate the model to output segments of text that closely resemble or replicate parts of its training data. This is particularly sensitive if the training data contained confidential or proprietary information.
- Reconstruction Attacks:
- Potential Use Against ChatGPT: Similar to model inversion, attackers might try to reconstruct input data (like specific text examples) that the model was trained on, based on the information the model provides in its outputs. However, given the vast and diverse dataset ChatGPT is trained on, reconstructing specific training data can be challenging.
- Property Inference Attacks:
- Potential Use Against ChatGPT: Attackers could analyze responses from ChatGPT to infer properties about its training data that aren’t explicitly modeled. For instance, if the model shows biases or tendencies in certain responses, it might reveal unintended information about the composition or nature of the training data.
- Model Stealing or Extraction:
- Potential Use Against ChatGPT: This involves querying ChatGPT extensively to understand its underlying mechanisms and then using this information to create a similar model. Such an attack would be an attempt to replicate ChatGPT’s capabilities without access to the original model or training data.
Integrity attacks on AI models like ChatGPT aim to compromise the accuracy and reliability of the model’s outputs. Let’s examine how these attacks could be or have been used against the ChatGPT model, categorized by the learning stage and attacker’s knowledge:
Attacks during Training Phase (White-Box):
- Data Poisoning: If an attacker gains access to the training pipeline, they could introduce malicious data into ChatGPT’s training set. This could skew the model’s understanding and responses, leading it to generate biased, incorrect, or harmful content.
- Backdoor Attacks: An insider or someone with access to the training process could implant a backdoor into ChatGPT. This backdoor might trigger specific responses when certain inputs are detected, which could be used to spread misinformation or other harmful content.
Attacks during Inference Phase (Black-Box):
- Adversarial Attacks: These involve presenting ChatGPT with specially crafted inputs that cause it to produce erroneous outputs. For instance, an attacker could find a way to phrase questions or prompts that consistently mislead the model into giving incorrect or nonsensical answers.
- Output Manipulation: This would involve intercepting and altering ChatGPT’s responses after they are generated but before they reach the user. While this is more of an attack on the communication channel rather than the model itself, it can still undermine the integrity of ChatGPT’s outputs.
Implications and Defense Strategies:
- During Training: Ensuring the security and integrity of the training data and process is crucial. Regular audits, anomaly detection, and secure data handling practices are essential to mitigate these risks.
- During Inference: Robust model design to resist adversarial inputs, continuous monitoring of responses, and secure deployment architectures can help in defending against these attacks.
Real-World Examples and Concerns:
- To date, there haven’t been publicly disclosed instances of successful integrity attacks specifically against ChatGPT. However, the potential for such attacks exists, as demonstrated in academic and industry research on AI vulnerabilities.
- OpenAI, the creator of ChatGPT, employs various countermeasures like input sanitization, monitoring model outputs, and continuously updating the model to address new threats and vulnerabilities.
In conclusion, while integrity attacks pose a significant threat to AI models like ChatGPT, a combination of proactive defense strategies and ongoing vigilance is key to mitigating these risks.
While these attack types broadly apply to all generative AI systems, the report notes that some vulnerabilities are particularly pertinent to specific AI architectures, like Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) systems. These models, which are at the forefront of natural language processing, are susceptible to unique threats due to their complex data processing and generation capabilities.
The implications of these vulnerabilities are vast and varied, affecting industries from healthcare to finance, and even national security. As AI systems become more integrated into critical infrastructure and everyday applications, the need for robust cybersecurity measures becomes increasingly urgent.
The NIST report serves as a clarion call for the AI industry, cybersecurity professionals, and policymakers to prioritize the development of stronger defense mechanisms against these emerging threats. This includes not only technological solutions but also regulatory frameworks and ethical guidelines to govern the use of AI.
In conclusion, the report is a timely reminder of the double-edged nature of AI technology. While it offers immense potential for progress and innovation, it also brings with it new challenges and threats that must be addressed with vigilance and foresight. As we continue to push the boundaries of what AI can achieve, ensuring the security and integrity of these systems remains a paramount concern for a future where technology and humanity can coexist in harmony.







Information security specialist, currently working as risk infrastructure specialist & investigator.
15 years of experience in risk and control process, security audit support, business continuity design and support, workgroup management and information security standards.





