Short Bytes: Deep Learning has high computational demands. To develop and commercialize Deep Learning applications, a suitable hardware architecture is required. There is a huge ongoing competition to develop efficient hardware platforms for Deep Learning application deployment. Here, we shall discuss specific hardware requirements and how the future looks for Deep Learning hardware.
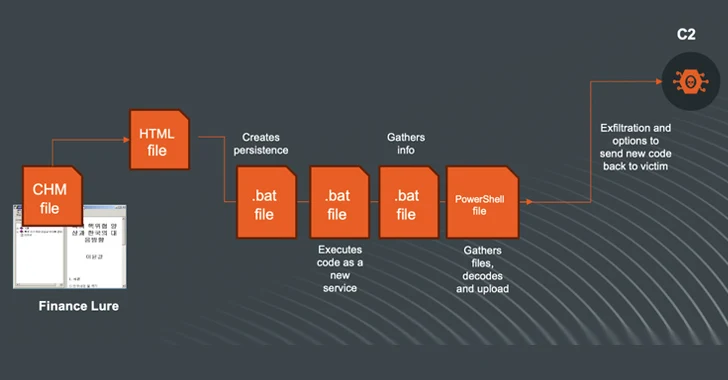
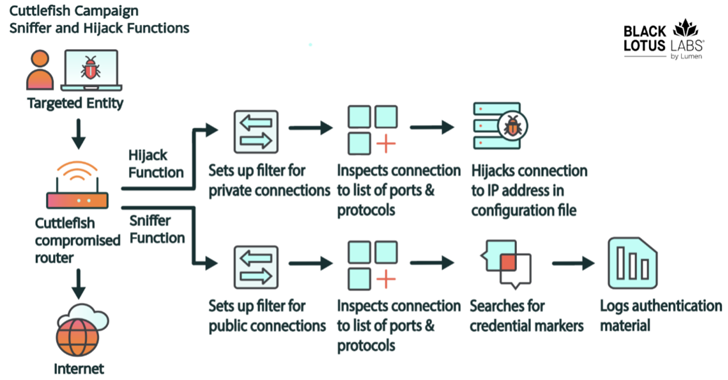
Deep Learning is the hottest topic of this decade and may as well be for forthcoming ones too. Although it may seem on the surface, Deep Learning is not all about math, creating models, learning and optimization. The algorithms must run on optimized hardware and learning tens of thousands of data may take a long time, even weeks. There is a growing need for faster and more efficient hardware for Deep Learning Networks.
It is easy to observe that not all processes run efficiently on a CPU. Gaming and Video processing requires dedicated hardware – the Graphics Processing Units (GPUs); Signal Processing requires separate architecture as that of Digital Signal Processors (DSPs) and so on. People have been designing dedicated hardware for learning; For instance, the AlphaGo computer that played GO against Lee Sedol in March 2016, used a distributed computing module consisting of 1920 CPUs and 280 GPUs. With NVIDIA announcing their new wave of Pascal GPUs, the focus is now balanced on both the software and hardware sides of Deep Learning. So, let’s focus on the hardware aspect of Deep Learning.
Requirements of Deep Learning Hardware Platform
To understand the hardware required, it is essential to understand how Deep Learning works. On its surface, a large dataset is obtained and a Deep Learning model is chosen. Every model has some intrinsic parameters to be tuned in order to learn that data. This tuning of parameters essentially comes down to an optimization problem in which the parameters are chosen so that a particular constraint is optimized.

Baidu’s Silicon Valley AI Lab (SVAIL) has proposed the DeepBench benchmark for Deep Learning hardware. The benchmark focusses on the hardware performance of fundamental computations rather than the learning models. This approach is aimed to find the bottlenecks which make the computations slower or inefficient. Therefore, the focus is on trying to devise an architecture that performs best on the basic operations used for training Deep Neural Networks. So what are those fundamental operations? Deep Learning algorithms today consists mostly of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). Based on these algorithms, DeepBench proposed four operations –
- Matrix Multiplication – This exists in almost all models of Deep Learning and is computationally intensive.
- Convolution – This is yet another commonly used operation and takes up most of the flops (Floating point operations per second) in the model.
- Recurrent Layers – These are feedback layers within the model and is essentially a combination of the previous two operations.
- All Reduce – This is a basically a sequence of operations to communicate or parse the learned parameters before optimization. This is specifically useful when performing synchronous optimization over a Deep Learning Network that is distributed across multiple hardware (as in the case of AlphaGo).
Apart from these, hardware accelerators for Deep Learning require features like Data level and pipelined parallelism, multithreading, and high memory bandwidth. Furthermore, As the training time for the data is high, the architecture must consume low power. Therefore, Performance per Watt is one of the evaluation criteria for the hardware architecture.
Current trends and Future scope

NVIDIA has been dominating the current Deep Learning market with its massively parallel GPUs and their dedicated GPU programming framework called CUDA. But there has been a growing number of companies developing accelerated hardware for Deep Learning. Google’s Tensor Processing Unit (TPU), Intel’s Xeon Phi Knight’s Landing, Qualcomm’s Neural Network Processor (NNU) are some examples. Companies like Teradeep are now starting to use FPGAs (Field-Programmable Gate Arrays) as they could be up to 10 times more power efficient than GPUs. FPGAs are more flexible , scalable and provide better Performance per Watt than GPUs. But programming FPGAs require hardware specific knowledge, so there have been recent developments on software-level FPGA programming models.
Moreover, there has been widespread notion that, there cannot be a unified architecture that is best suited for all models since different models require different hardware processing architectures. Researchers are trying to challenge this notion with the use of FPGAs.
With most of the Deep Learning software frameworks (like TensorFlow, Torch, Theano, CNTK) being Open Source, and Facebook recently Open Sourcing its ‘Big Sur’ Deep Learning hardware, we can expect many such Open Source Hardware Architectures for Deep Learning in the near future. In the follow-up posts, we will discuss more specific Deep Learning hardware that are available today. So what do you think about Deep Learning hardware? Share it with us in the comments.
Also Read: What Is Open Source Hardware And Why Should You Care?