Matías Porolli shows how exploit another classic buffer overflow vulnerability, in which the ebp register is moved to execute an arbitrary code.
A few weeks ago, we published a challenge relating to the exploitation of a simple buffer overflow in Linux. In the published solution, it was noted how it was possible to change the execution flow of the vulnerable program, with cursor overwrite in the next instruction as a result of the buffer overflow. Today, we will show how to exploit another classic buffer overflow vulnerability, in which the ebp register is moved to execute an arbitrary code.
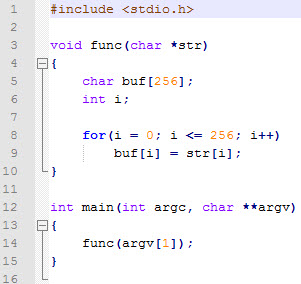
Let’s look at the code above, where we can find at least two programming errors. Firstly, the copy loop will always move the same quantity of bytes, regardless of the length of the chain to be copied. Secondly, and more importantly, the loop comparison is wrong: the buffer has 256 bytes and the copy loop 257, moving the least significant byte of what follows it immediately in the memory (the ebp value stored by main).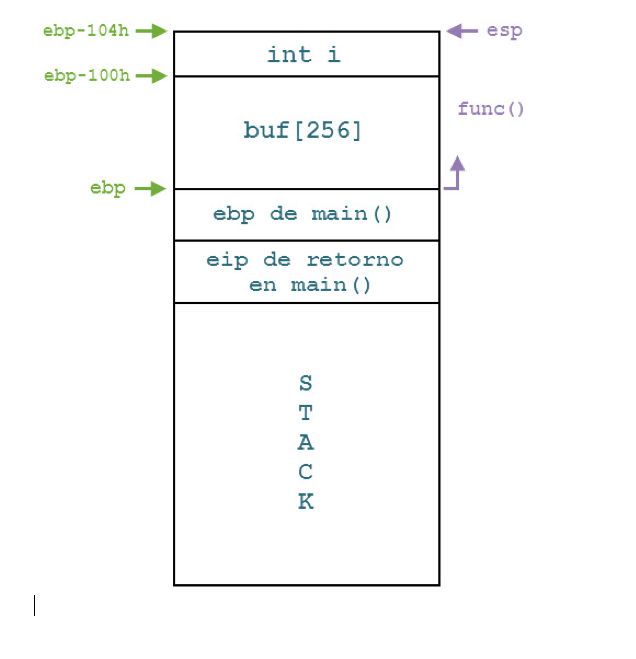
As can be seen in the above diagram, the return address is stored after ebp. The idea of exploiting this vulnerability involves modifying ebp to point to a part of the buffer where a return address can be read from, and at the same time, points to the payload within the same buffer.

In the disassembly, we can see that after leaving the copy loop (moving ebp) two instructions are executed: leave and ret. The leave instruction reestablishes the stack frame of main(); leave is equivalent to mov %ebp,%esp and pop %ebp, i.e., the opposite of the first two instructions of func(). Once EBP has been altered, the ret instruction takes the eip value from another location, and not the original location in the stack.
If we test run the application with 256 letter “A”s as the argument, ebp is moved with the null byte at the end of the chain (byte 257), meaning that the return address is taken from the buffer full of “A”s, generating an error as the address 0x41414141 (“A” = 0x41) does not exist.
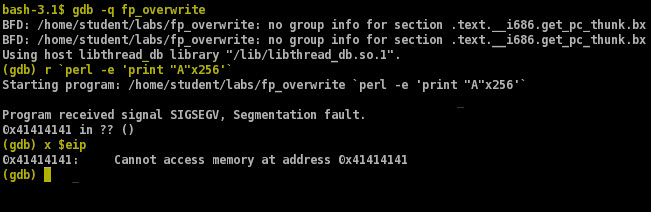
If we place a breakpoint immediately after the original ebp value in the stack, we can see that it is 0xbffff3f8. We can also see that it is followed in the memory by the original return address in main(), 0x08048261. We can then place a breakpoint before the leave instruction is executed and see that the ebp value stored is now 0xbffff300.
It is important to note that the buffer is between 0xbffff2ec and 0xbffff3ec, so the modified ebp address is useful, as it is within the buffer. Once leave has been executed, we can then check it is aimed at the desired address:

To construct the shellcode we will:
- Place junk bytes from 0x2ec up to 0x300, i.e., 20 padding bytes. We can place NOP (0x90), for example.
- At 0x300. it will target our new ebp, therefore we can fill it with four more junk bytes.
- In 0x304, we can place the address of the shell inside our buffer, e.g., 0xbffff308.
- In 0x308, the shell begins.
- The remaining 256 bytes are filled.

After execution, we can see that the shell is opened within gdb.

In forthcoming instalments, we will be seeing techniques of increasing complexity.
Image credits: ©Jan Ramroth/Flickr