MercadoLibre, one of the most important e-commerce companies in Latin America, confirmed unauthorized access to a part of its source code, in addition to confirming that the attackers managed to access the personal records of some 300,000 users. The company has not confirmed that its IT infrastructure was affected during the incident.
The Argentine firm confirmed the compromise of its systems after hackers from the Latin American group Lapsus$ threatened to expose confidential information from MercadoLibre and other e-commerce platforms. Faced with this threat, MercadoLibre enabled all its security and containment protocols, so it recommended that users of the platform change their passwords and monitor their account statements to prevent any attempt at malicious activity.
MercadoLibre has established itself as the largest e-commerce and payment processing ecosystem in Latin America. It currently has more than 140 million active buyers and sellers in Argentina, Brazil, Chile, Colombia, Mexico, Peru and Venezuela.
As mentioned above, Lapsus$ has been credited with the commitment of some 24,000 source code repositories operated by MercadoLibre and Mercado Pago. Through a Telegram channel, threat actors published a survey for their subscribers to decide if they should leak the company’s information. In addition to MercadoLibre, hackers are threatening to leak information from Vodafone and Impresa.
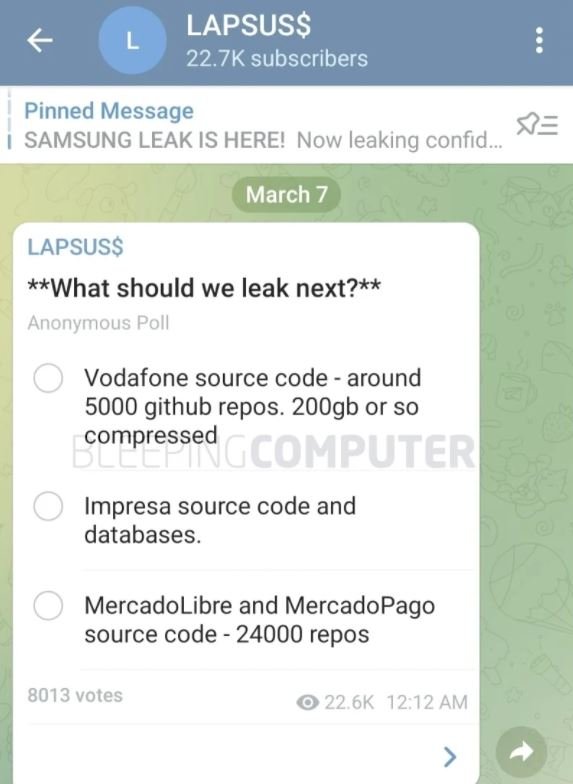
This is pretty much the same tactic the cybercriminal group followed by exposing more than 190GB of sensitive information belonging to Samsung. A week ago, the South Korean tech firm confirmed that Lapsus$ managed to compromise its systems, stealing files with details about the source code of the Galaxy family of smartphones.
Cybersecurity specialists report that extortion groups like Lapsus$ steal information from victims and, unlike ransomware operations, these hackers threaten to expose stolen sensitive information on dark web forums if the affected companies do not pay a ransom.
A couple of weeks ago, Lapsus$ also claimed responsibility for the attack on NVIDIA, a technology firm dedicated to the manufacture of chips. The incident resulted in the theft of more than 71,000 NVIDIA employee credentials, some of which were leaked on hacking forums.
To learn more about information security risks, malware variants, vulnerabilities and information technologies, feel free to access the International Institute of Cyber Security (IICS) websites.









He is a well-known expert in mobile security and malware analysis. He studied Computer Science at NYU and started working as a cyber security analyst in 2003. He is actively working as an anti-malware expert. He also worked for security companies like Kaspersky Lab. His everyday job includes researching about new malware and cyber security incidents. Also he has deep level of knowledge in mobile security and mobile vulnerabilities.