All posts tagged "Crawler"
-
 205News
205NewsGoogle Open Sources Its ‘Web Crawler’ After 20 Years
Google’s Robot Exclusion Protocol (REP), also known as robots.txt, is a standard used by many websites to tell the automated crawlers which...
-
Information Gathering
ACHE – A Web Crawler For Domain-Specific Search
ACHE is a focused web crawler. It collects web pages that satisfy some specific criteria, e.g., pages that belong to a given...
-
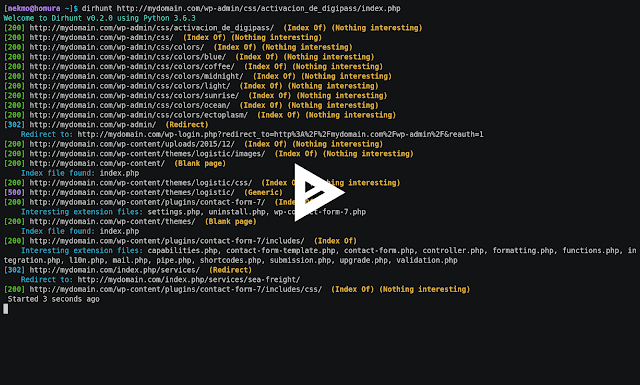 240Information Gathering
240Information GatheringDirhunt v0.6.0 – Find Web Directories Without Bruteforce
DEVELOPMENT BRANCH: The current branch is a development version. Go to the stable release by clicking on the master branch. Dirhunt is...
-
 261Security Tools
261Security ToolsEKFiddle v.0.8.2 – A Framework Based On The Fiddler Web Debugger To Study Exploit Kits, Malvertising And Malicious Traffic In General
A framework based on the Fiddler web debugger to study Exploit Kits, malvertising and malicious traffic in general. Installation Download and install...
-
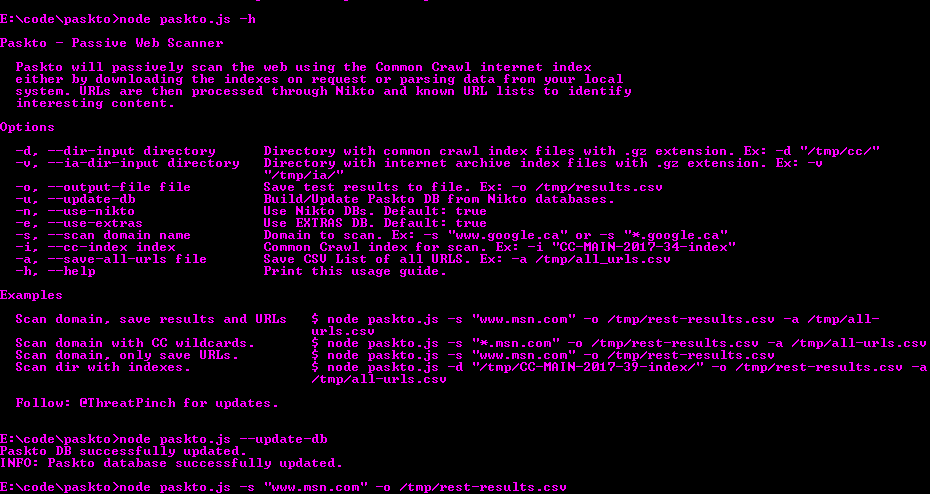 235Vulnerability Analysis
235Vulnerability AnalysisPaskto – Passive Web Scanner
Paskto will passively scan the web using the Common Crawl internet index either by downloading the indexes on request or parsing data...
-
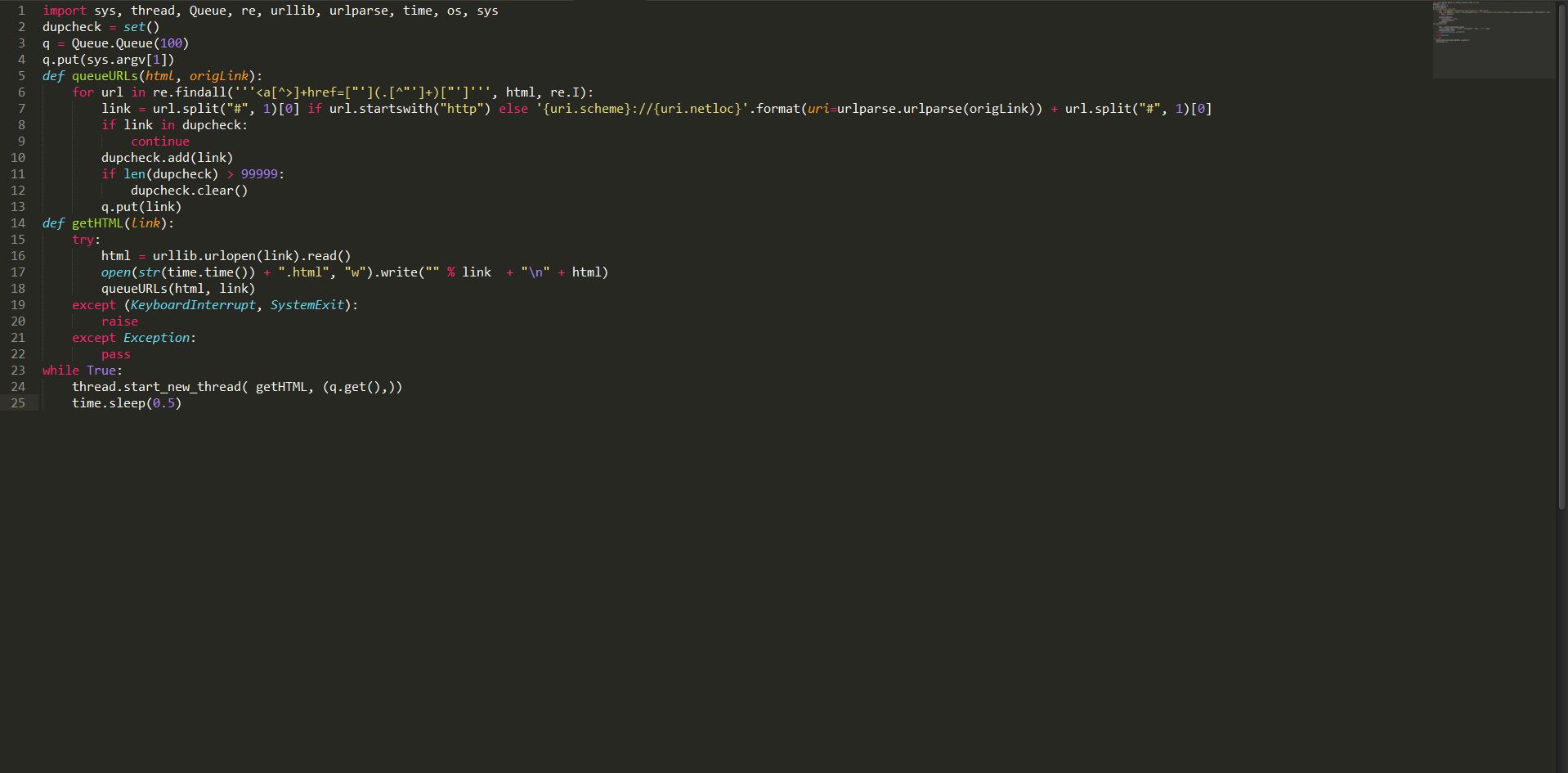 291Geek
291GeekHow to Build a Basic Web Crawler in Python
Short Bytes: Web crawler is a program that browses the Internet (World Wide Web) in a predetermined, configurable and automated manner and performs...